制作Weibo & Wechat词云
18 Sep 2018受到Liuzhujun同学的博客启发,想探究一下自己的微博究竟写了些什么东西?基于原博客的代码,有些地方稍作改动。以滤波器本人微博为例,结果是这样的:

-
featurecode这个域似乎没有用了。有用的域只剩下uid和container_id。 -
修改了raw html预处理的正则表达。使之成为:
pattern1 = re.compile(r'<.*?>|>|"|转发微博|网页链接|Repost|(分享|查看|刚刚).*(图片|专辑|单曲|歌曲|照片|视频)') pattern2 = re.compile(r'/@[^\s]+/|/+@[^\n]+') pattern3 = re.compile(r'[((].*@[^\s]+[))]|[??]|、|[!!]') text = re.sub(pattern3, '', re.sub(pattern2, '', re.sub(pattern1, '', raw_html)))作为重度分享患者,pattern1和3去掉各种:来自@网易云音乐,来自@虾米音乐,刚刚在IG上上传了xxx图片/视频,分享了xxx的歌曲xxx,等等垃圾信息。而pattern2去掉了过长的转发时转发内容的垃圾信息,例如:@aa:123//@bb:234//@cc:345
-
修改Jieba的Stop Words。这里整理了来自Baiduguide和xpo6的中英文Stop Words,合成一个文件,可以在这里下载。
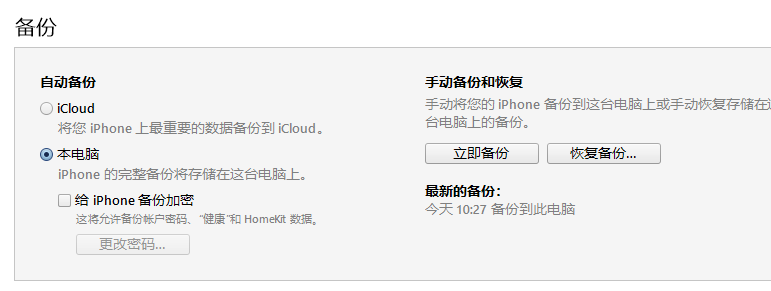
同理,我们是不是也可以针对微信的聊天记录制作词云呢?答案是可以!首先需要做的就是把聊天记录给提取出来。这里以iOS系统微信为例,首先打开iTunes,点击手机小图标,选择“本电脑”,再点击“立即备份”按钮开始备份。
然后下载iTools,选择工具箱->iTunes备份管理,选择已备份的文件,进入var/mobile/Applications/com.tencent.xin/,将Documents文件提取出来。Documents文件中有一个一长串数字+字母的文件夹,打开后在DB文件下能找到MM.sqlite,这就是最关键的聊天记录数据库了,可供处理。
当然,也有另外一种捷径方法:进入工具箱->微信管理,然后选择已备份的项目,直接可以分析微信聊天记录,并且导出为txt。虽然该软件稍微有些流氓,但是已经是所有软件中最良心的一个了,还不需要花钱…(可以把广告费结了吗?)
恢复出来的文件可读性非常高,可以利用一些规则来提取你想要的内容。需要注意的是源文件是GB2312编码的,记得转换为UTF-8更好哦~
滤波器本器只需要统计词频,并没有关键字处理的需求,因此只需要将日期时间与杂项剔除即可:
data = []
jieba.analyse.set_stop_words("stopwords.txt")
pattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}|接收|发送|未知类型|网页消息|系统通知|文字|表情|图片|视频|我|[??]|、|[!!]|。')
with open("xxx.txt") as f:
mytext = f.readlines()
for line in mytext:
line = re.sub(pattern, '', line)
data.extend(jieba.analyse.extract_tags(line, topK=20))
data = " ".join(data)
wordcloud = WordCloud(width=640,
height=480,
collocations=False,
font_path='Songti',
background_color='white',
).generate(data)
Weibo版完整代码如下,其中Prerequisite为:
- jieba
- matplotlib
- pyparsing
- requests
- wordcloud
Wechat版完整代码如下